The Unified Agentic Stack: A Complete Blueprint for Production AI
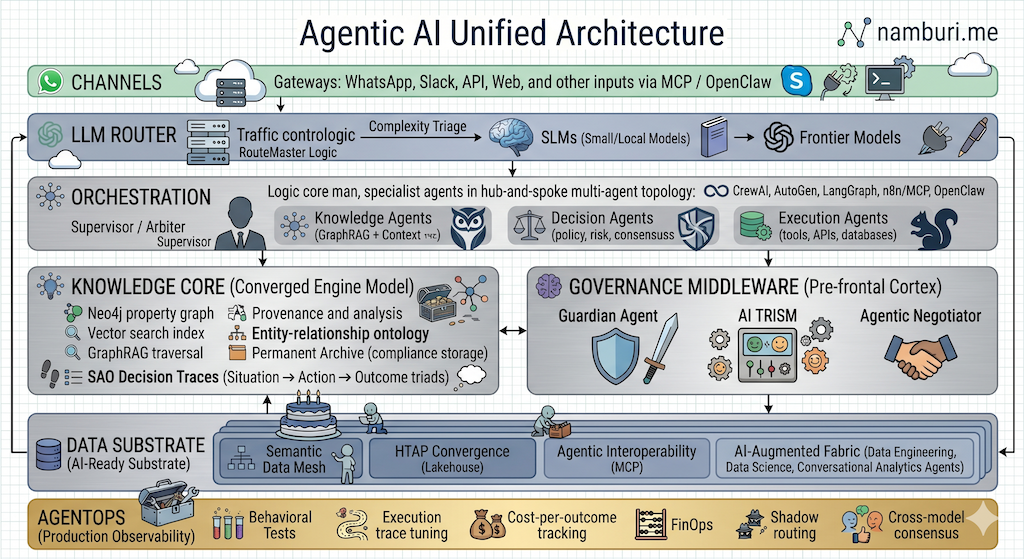
Enterprise AI is littered with half-built stacks. Teams ship a GraphRAG prototype — but with no governance layer, every agent action is a compliance liability. They build an orchestrator — but with no inference cost discipline, every query hits a frontier model and the bill compounds quietly. They deploy agents — but with no memory, no audit trail, and no operational discipline, every production incident starts with "we don't know what the agent did or why." Three failure modes. One root cause: components built in isolation, stitched together without a principled architecture.
Why a Unified View?
The unified stack is the antidote. Six layers, each owning a single concern, each independently replaceable, all tightly coordinated. Build in sequence — bottom to top — and every layer you add makes the one below it more powerful.
Layer 1 — Channels: The Universal Input Gateway
WhatsApp, Slack, REST APIs, web apps, event streams — all arriving in different formats. Each channel exposes an MCP (Model Context Protocol) server; agents consume every surface through the same tool-call protocol, so adding a new channel is an MCP server implementation, not a new integration pattern.
Layer 2 — LLM Router: The Intelligence Backbone
The first decision is not what to answer — it's which model should answer it. Intelligent routing keeps the majority of requests on fast, local SLMs and escalates to frontier models only when task complexity genuinely requires it. In a governed stack, data sensitivity and regulatory jurisdiction influence routing decisions alongside complexity.
Small / Local Models
Fine-tuned for precision — tool calls, schema adherence, structured output, agent loops. Runs locally, low latency. The default for runtime-layer tasks.
Large / Frontier Models
Open-ended reasoning, ambiguous intent, novel synthesis. Escalated to when the task genuinely exceeds what a specialist can handle.
Layer 3 — Orchestration: The Central Brain
A Supervisor (Arbiter) decomposes goals into sub-tasks and routes each to the right specialist. CrewAI, AutoGen, and LangGraph each bring distinct strengths — role-based crew orchestration, multi-agent deliberation, and graph-driven stateful workflows respectively — though all three overlap significantly in capability. The right choice depends on workflow topology, not a single capability gap. YAML-driven routing keeps workflow logic out of code entirely.
Knowledge Agents
Retrieve verified, grounded context from the Knowledge Core — graph queries, semantic search, decision history.
Decision Agents
Evaluate context against policy and risk. High-stakes decisions require Cross-Model Consensus before clearing.
Execution Agents
Take real-world action — APIs, databases, CRM — only after Knowledge and Decision agents have cleared the path.
Layer 4 — Knowledge Core: Grounded, Relational, Persistent
Not a database — a Converged Engine. GraphRAG traverses entity relationships that vector search cannot; SAO Decision Traces store every agent interaction as a Situation → Action → Outcome triad, making every past decision queryable. The archive closes the loop into model retraining.
Verified Facts
Context Graph — multi-hop reasoning, stronger grounding, and lower hallucination risk.
Unstructured Search
Vector embeddings + NL-to-Cypher. Plain English in, structured queries out.
Experiential Memory
Every agent decision — durable, auditable, queryable. Governance as infrastructure.
Compliance & Retraining
Cold storage for audit retention. Yesterday's outcomes become tomorrow's training signal.
Layer 5 — Governance Middleware: The Runtime Policy Layer
Traditional governance is a gate — it blocks until a human approves, which breaks at agent speed. This layer replaces the gate with four concrete mechanisms. The Guardian Agent evaluates reasoning against machine-verifiable contracts before any action fires. The TRiSM layer classifies each request by data sensitivity and real-time risk score, restricting access to high-sensitivity paths before a tool call is issued. The Agentic Negotiator resolves policy violations inline by substituting a compliant alternative — masked data, a permitted endpoint, a redacted response — when policy allows it. The HITL Gate handles the irreducible cases: it pauses the agent with full context preserved so a human can approve and the workflow resumes exactly where it stopped. Most violations resolve at the Negotiator; the HITL Gate exists for the decisions that genuinely require human judgment. See the Negotiator and TRiSM posts for the full patterns.
| Component | Role | What it does |
|---|---|---|
| Guardian Agent | Runtime safety | Evaluates reasoning against machine-verifiable contracts before any action fires; blocks non-compliant calls at the reasoning step |
| TRiSM Layer | Trust & Risk | Classifies requests by data sensitivity via DSPM; computes real-time risk scores; restricts high-sensitivity data paths before tool calls are issued |
| Agentic Negotiator | Policy resolver | Intercepts policy violations; substitutes compliant alternatives (masked data, permitted endpoints, redacted responses) inline when policy allows; escalates to HITL when no inline resolution exists |
| HITL Gate | Human escalation | Stateful pause for decisions that require human judgment; full agent context preserved so the workflow resumes exactly where it stopped after approval |
Layer 6 — Data Substrate: The AI-Ready Foundation
Everything above depends on clean, semantically consistent data below. The four-pillar substrate builds this in sequence — each pillar enabling the next: Semantic Data Mesh (agreed definitions across domains) → HTAP Lakehouse (real-time reads, no ETL lag) → Storage Adapter Layer (each backend — lakehouse, vector store, graph DB — exposes an MCP server; agents use the same tool-call interface as Layer 1, so swapping a storage engine means replacing one MCP server, not rewriting agent code) → AI-Augmented Fabric (agents that maintain the data layer itself).
AgentOps: The Discipline That Ships
Architecture without operations is a whiteboard. AgentOps makes the stack production-grade: behavioral testing validates decision quality, not just output format; cost-per-outcome tracking applies FinOps at agent granularity; SAO trace-driven tuning turns every failure into a training signal; shadow routing validates changes against live traffic before they go live.
Three Principles Behind Every Layer
Grounding over Generation
Retrieve verified facts before reasoning — not as a filter, but as step one. A confident wrong answer is worse than an uncertain right one.
Governance as Velocity
The right governance layer removes blockers rather than creating them. Security and speed are only in tension when the layer between them is unintelligent.
Role before Technology
Define agents by business function, evaluate them on business outcomes. "What role does this agent play?" is a better first question than "which model should I use?"
A more capable model widens what an agent can reason about. It does not give you an audit trail, prevent data egress violations, reduce per-query cost, or make your knowledge graph more accurate. Those are orthogonal concerns — and this stack is where they get resolved.
Build the Unified Agentic Stack: The Architecture Is the Strategy
The counterargument is real: a sufficiently capable model, prompted well, can handle a wide range of tasks without a six-layer stack. That is true for prototypes. At production scale the failure modes are different — a better model does not stop an agent from exfiltrating regulated data, does not cap your inference bill, does not recover a multi-step pipeline when one tool call fails. The layers here exist because each one solves a problem that is orthogonal to reasoning quality: governance knows data classification from the substrate; routing consults governance constraints, not just task complexity; memory feeds the Knowledge Core's retraining signal. The compounding is real, but it is compounding of specific capabilities, not a general claim about "interconnectedness."
Start at the bottom. Get the data substrate right before you build the Knowledge Core. Deploy Governance Middleware before you give agents real execution permissions. Add AgentOps before you scale. The order matters because each layer depends on the one below — and that dependency only pays off if the layers were designed to share state from the start.