Maximizing ROI: The Strategic Shift to Intelligent LLM Routing
In the current AI landscape, many enterprises are inadvertently over-provisioning their compute resources. Defaulting every query to flagship models like GPT-4 or Claude 3.5 is the digital equivalent of using a sledgehammer to crack a nut—effective, but unnecessarily expensive. Emerging research from ICLR 2024 (Hybrid LLM) and ICML 2025 (BEST-Route) points to a more sophisticated approach: Intelligent LLM Routing. This strategy optimises the trade-off between high-tier reasoning and operational cost by dynamically directing traffic across a model ensemble.
Predictive Selection
- Triage every query in real-time
- Difficulty signals drive model choice
Hybrid LLM
- Binary SLM-or-frontier routing
- Up to 60–80% cost reduction
BEST-Route
- Best-of-N sampling from SLM
- Near-frontier accuracy at SLM cost
4-Step Architecture
- Profile → Tier → Train → Monitor
- Shadow routing before full commit
The Core Pattern: Predictive Selection
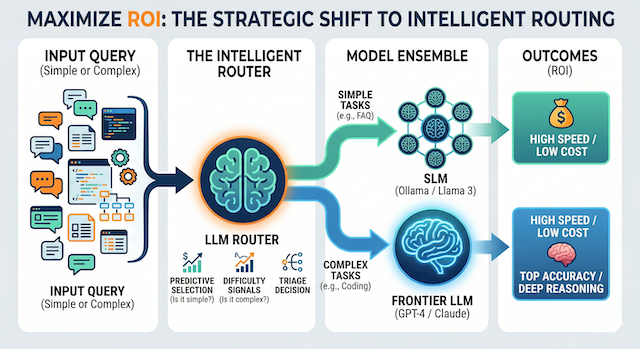
An LLM Router functions as an intelligent traffic controller. Positioned between the user and the inference engine, it analyses prompt complexity in real-time. By predicting the "hardness" of a task, it ensures that only high-complexity queries consume premium tokens, while simpler tasks are offloaded to efficient, small language models (SLMs).
Think of it as a triage system: the router continuously evaluates incoming requests against learned difficulty signals—token length, syntactic complexity, domain specificity, and historical accuracy patterns—before committing to a model tier.
Two Validated Routing Strategies
Binary Model Selection
Utilises binary routing to decide between a "Small" or "Large" model. If a prompt can be handled by a model like Phi-3 or Llama 3, the router bypasses the expensive frontier model entirely.
- Signal: Classifier predicts task difficulty from prompt features
- Decision: Binary — route to SLM or frontier LLM
- Outcome: Up to 60–80% token cost savings
Best-of-N Sampling
Generates multiple responses from a smaller model, then uses a reward model to select the optimal output—achieving frontier-level performance at a fraction of the cost.
- Signal: Reward model scores N candidate outputs from an SLM
- Decision: Accept best SLM output, or escalate if confidence is low
- Outcome: Near-GPT-4 accuracy at SLM pricing
High-Impact Use Cases
Tiered Resolution
FAQs handled by local SLMs (Ollama/vLLM); nuanced technical queries escalate to frontier models. Lower cost per ticket with no drop in quality for complex issues.
Contextual Routing
GNN-based routers adapt model selection to historical user preferences and domain vocabulary—a power user gets a different routing profile than a first-time visitor, automatically.
Modal Orchestration
Mixed-media requests decomposed by the router, dispatched to specialist vision, audio, or text models, and synthesised transparently—no client-side changes required.
Implementation with the LLMRouter Framework
For engineering teams looking to operationalise these strategies, the LLMRouter open-source library provides a production-ready toolkit:
- Unified CLI: Streamlines the training and deployment of custom routers via
llmrouter train, abstracting away dataset preparation and hyperparameter tuning. - Advanced Reward Modeling: Integrates scoring mechanisms (such as
armoRM) to predict response quality during inference, enabling BEST-Route without custom reward model development. - Seamless Integration: Features OpenAI-compatible API servers, enabling immediate deployment to platforms like Slack, Discord, or proprietary web applications without client-side changes.
Building a Routing-Aware Architecture
Adopting intelligent routing is not simply a model swap—it requires a deliberate architectural shift:
Profile Your Workload
Analyse your query distribution. In most enterprise deployments, fewer than 20–30% of queries require frontier-model reasoning. Establishing this baseline shapes your routing thresholds.
Define Model Tiers
Select your SLM (e.g., Phi-3 Mini, Llama 3 8B) and frontier model. Consider latency, privacy requirements, and data residency when choosing between hosted APIs and on-premise inference with vLLM or Ollama.
Train or Fine-Tune the Router
Use labelled difficulty annotations or proxy signals (user satisfaction, re-query rate) to train your routing classifier. The LLMRouter CLI simplifies this step considerably.
Monitor and Iterate
Deploy with shadow routing first—log router decisions alongside a baseline (all-frontier) deployment and compare outcomes. Refine difficulty thresholds based on real production data before fully committing.
Routing Within the Governed Agentic Stack
Intelligent routing doesn't operate in isolation. In a production agentic architecture, the models being routed are answering questions grounded in your Knowledge Core—the verified, relationship-rich data layer that makes agent responses accurate at the individual and operational level. Routing policy should therefore account for more than task complexity: data sensitivity tier, regulatory constraints on which model may process which data classification, and the agent's own permission boundary are all governance signals that belong in the routing decision.
In an architecture shaped by an AI-first data strategy, the router becomes a governance control point—a place where compliance requirements, cost discipline, and performance targets are enforced simultaneously rather than managed as separate concerns across different teams.
The Bottom Line
The most competitive AI stacks will not rely on a single "God Model." Success lies in an orchestrated ensemble of specialised models, managed by an intelligent routing layer that prioritises both precision and fiscal responsibility. Enterprises that embrace this pattern today are not just cutting costs—they are building a more resilient, scalable, and explainable AI infrastructure for the long term.